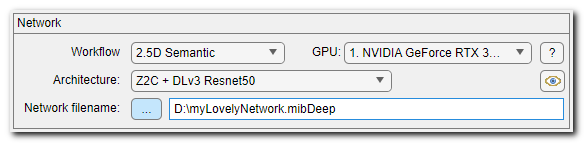
DeepMIB - Network panel
The upper part of DeepMIB is occupied with the Network panel. This panel is used to select workflow and convolutional network architecture to be used during training
Back to Index --> User Guide --> Menu --> Tools Menu --> Deep learning segmentation
Contents
-
Workflows -
2D Semantic workflow -
2.5D Semantic workflow -
3D Semantic workflow -
2D Patch-wise workflow -
Network filename -
The GPU ▼ dropdown -
The Eye button
Workflows
Start a new project with selection of the workflow:- 2D Semantic segmentation, where 2D image pixels that belong to the same material are clustered together.
- 2.5D Semantic segmentation, where 2D network architectures are used as a template to process small (3-9 stacks) subvolumes, where only the central slice is segmented
- 3D Semantic segmentation, where 3D image voxels that belong to the same material are clustered together.
- 2D Patch-wise segmentation, where 2D image is predicted in blocks (patches) resulting a heavy downsampled image indicating positions of objects of interest
2D Semantic workflow
Application of DeepMIB for 2D semantic segmentation of mitochondria on TEM images

List of available network architectures for 2D semantic segmentation
- 2D U-net, is a convolutional neural network that was
developed for biomedical image segmentation at the Computer Science
Department of the University of Freiburg, Germany. Segmentation of a 512
x 512 image takes less than a second on a modern GPU (Wikipedia)
References:
- Ronneberger, O., P. Fischer, and T. Brox. "U-Net: Convolutional Networks for Biomedical Image Segmentation." Medical Image Computing and Computer-Assisted Intervention (MICCAI). Vol. 9351, 2015, pp. 234-241 (link)
- Create U-Net layers for semantic segmentation (link)
- 2D SegNet, is a convolutional network that was
developed for segmentation of normal images University of Cambridge, UK.
It is less applicable for the microscopy dataset than U-net.
References:
- Badrinarayanan, V., A. Kendall, and R. Cipolla. "Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation." arXiv. Preprint arXiv: 1511.0051, 2015 (link)
- Create SegNet layers for semantic segmentation (link) - 2D DeepLabV3 Resnet18/Resnet50/Xception/Inception-ResNet-v2, (recommended) an efficient DeepLab v3+ convolutional neural network for
semantic image segmentation initialized with selectable base network. Suitable for large variety
of segmentation tasks. The input images can be grayscale or RGB colors.
- Base networks:
- Resnet18 initialize DeepLabV3 using ResNet-18, a convolutional neural network that is 18 layers deep with original image input size of 224 x 224 pixels.
This is the lightest available version that is quickest and has lowest
GPU requirements. The network is intialized using a pretrained for EM or pathology
template that is automatically downloaded the first time the network is used.
ResNet-18 reference:
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016 - Resnet50 initialize DeepLabV3 using ResNet-50, a convolutional neural network that is 50 layers deep with original image input size of 224 x 224 pixels.
The most balanced option for moderate GPU with good performance/requirements ratio. The network is intialized using a pretrained for EM or pathology
template that is automatically downloaded the first time the network is used.
ResNet-50 reference:
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016 - Xception [MATLAB version of MIB only]
initialize DeepLabV3 using Xception, a convolutional neural network that
is 71 layers deep with original image input size of 299 x 299 pixels.
Xception reference:
Chollet, Francois, 2017. "Xception: Deep Learning with Depthwise Separable Convolutions." arXiv preprint, pp.1610-02357. - Inception-ResNet-v2 [MATLAB version of MIB only] initialize DeepLabV3 using Inception-ResNet-v2, a convolutional neural network that
is 164 layers deep with original image input size of 299 x 299 pixels.
This network has high GPU requirements, but expected to provide the best results.
Inception-ResNet-v2 reference:
Szegedy Christian, Sergey Ioffe, Vincent Vanhoucke, and Alexander A. Alemi. "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning." In AAAI, vol. 4, p. 12. 2017.
Reference:
- Chen, L., Y. Zhu, G. Papandreou, F. Schroff, and H. Adam. "Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation." Computer Vision - ECCV 2018, 833-851. Munic, Germany: ECCV, 2018. (link)
- Resnet18 initialize DeepLabV3 using ResNet-18, a convolutional neural network that is 18 layers deep with original image input size of 224 x 224 pixels.
This is the lightest available version that is quickest and has lowest
GPU requirements. The network is intialized using a pretrained for EM or pathology
template that is automatically downloaded the first time the network is used.
2.5D Semantic workflow
Architectures available in 2.5D workflows
Depth to Color
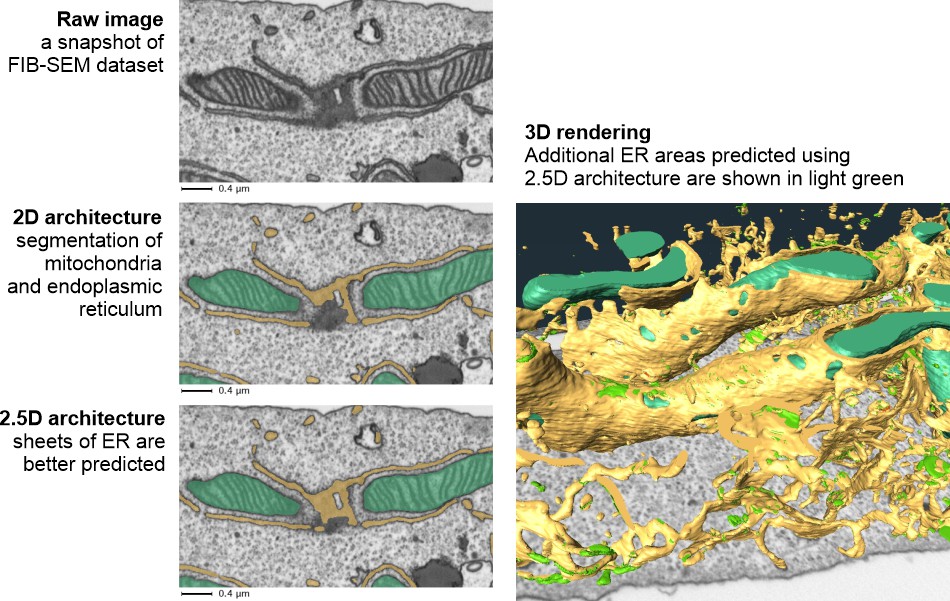
In this mode subslices are arranged as color channels for sstandard 2D architectures. Typically, this improves the segmentation results but with the cost of x1.4-1.6 slower training.A scheme below illustrates this:

Comparison of segmentation results achieved using 2.5D vs 2D architectures:
Available Depth to color architectures (for details please check the 2D semantic segmentation section above):
- Z2C + U-net, a standard U-net architecture is used as the template
- Z2C + DLv3 Resnet18, DeepLab v3 architecture based on Resnet 18
- Z2C + DLv3 Resnet50, DeepLab v3 architecture based on Resnet 50
3D convolutions for substacks
in this mode the substacks are processed using 3D convolutions. As the 3D convolutions are quite slow, this mode is significantly slower than 2D or 2.5 Z2C approaches.Available architectures:
- 3DC + DLv3 Resnet 18, an adapted for 2.5D approach DeepLab v3 architecture based on Resnet 18
Notes on application of 2.5D workflows
Work with the 2.5D workflows is essentially the same as with the 2D workflows, however there
- Input images and labels, should be a small (3-9 sections) substacks, where only the central slice is segmented. Each substack should be saved in a separate file
- Preprocessing is not implemented
- Generation of patches for training, the subvolumes for
traininig can be automatocally generated using:
- From models: Menu->Models(or Masks)->Model (Mask) statistics->detect obkects->right mouse click->Crop to a file
- From annotations: Menu->Models->Annotations->right mouse click over the selected annotations->Crop out patches around selected annotations
- Check this youtube video: https://youtu.be/QrKHgP76_R0?si=j_58ipCpp6Sn7r11
3D Semantic workflow
3D Semantic workflow is suitable for anisotropic and slightly anisotropic 3D datasets, where information from multiple sections is utilized to train a network for better prediction of 3D structures.
List of available network architectures for 3D semantic segmentation
- 3D U-net, a variation of U-net, suitable for for semantic
segmentation of volumetric images.
References:
- Cicek, Ö., A. Abdulkadir, S. S. Lienkamp, T. Brox, and O. Ronneberger. "3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation." Medical Image Computing and Computer-Assisted Intervention, MICCAI 2016. MICCAI 2016. Lecture Notes in Computer Science. Vol. 9901, pp. 424-432. Springer, Cham (link)
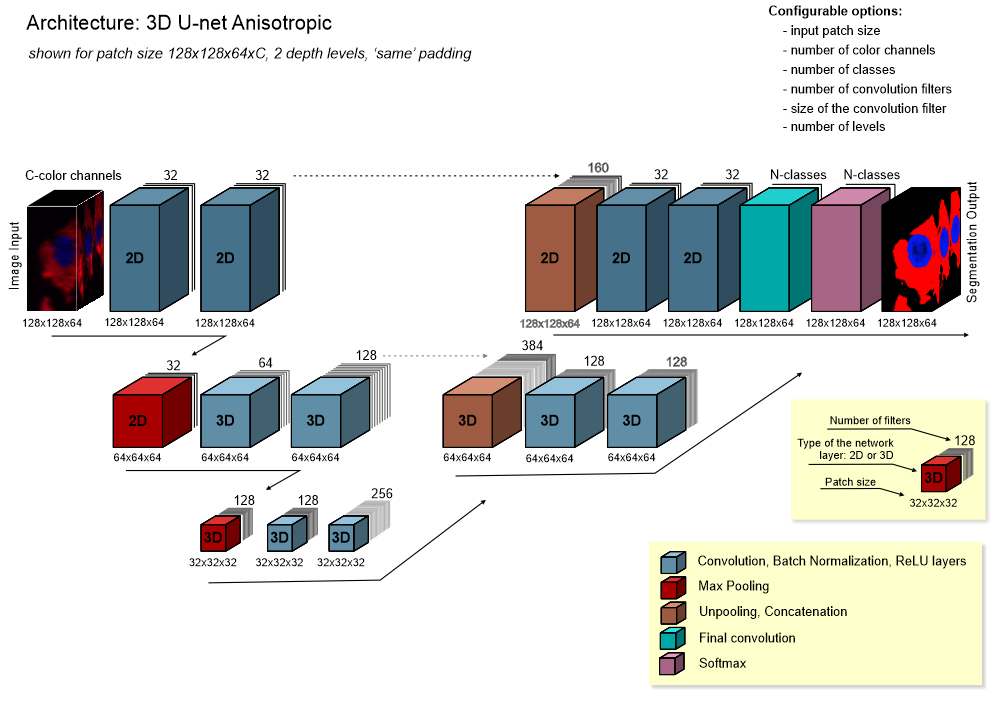
- Create 3-D U-Net layers for semantic segmentation of volumetric images (link) - 3D U-net anisotropic, a hybrid U-net that is a combination of 2D and 3D U-nets. The top layer of the network has 2D convolutions and 2D max pooling operation, while the rest of the steps are done in 3D. As result, it is better suited for datasets with anisotropic voxels
Architecture of 3D U-net anisotropic
2D Patch-wise workflow
In the patch-wise workflow the training is done on patches of images, where each image contains an example of a specific class.
During prediction, the images are processed in blocks (with or without an overlap) and each block is assigned to one or another class.
This workflow may be useful to quickly find areas where the object of interest is located or to target semantic segmentation to some specific aras.
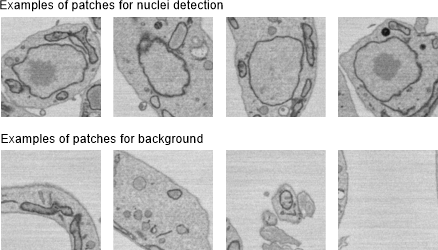
Detection of nuclei using the 2D patch-wise workflow
Examples of patches for detection of nuclei using the 2D patch-wise workflow:
Snapshot showing result of 2D patch-wise segmentation of nuclei.
- Green color patches indicate predicted locations of nuclei
- Red color patches indicate predicted locations of background
- Uncolored areas indicate patches that were skipped due to dynamic masking

Detection of spots using the 2D patch-wise workflow
The images below show examples of patches of two classes: "spots" and "background" using for training.
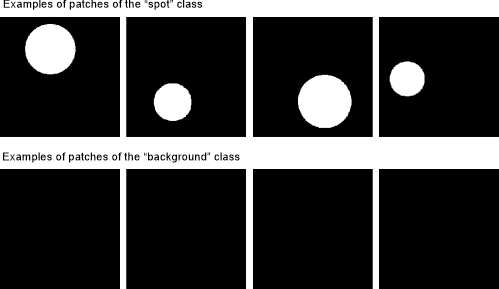
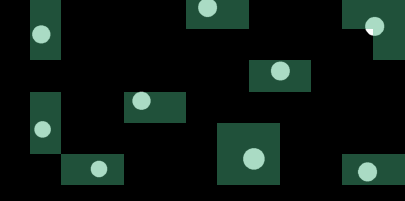
Synthetic example showing detection of spots using the patch-wise workflow.
List of available networks for the 2D patch-wise workflow
Comparison of different network architectures
Indicative plot of the relative speeds of the different networks (credit: Mathworks Inc.):

Resnet18 a convolutional neural network that is 18 layers deep. It is fairly light network, which is however capable to give very nice results. The default image size is 224x224 pixels but it can be adjusted to any value.
This network in MIB for MATLAB can be initialized using a pretrained version of the network trained on more than a million images from the ImageNet database.
References
- ImageNet. http://www.image-net.org
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
Resnet50 a convolutional neural network that is 50 layers deep. The default image size is 224x224 pixels but it can be adjusted to any value.
This network in MIB for MATLAB can be initialized using a pretrained version of the network trained on more than a million images from the ImageNet database.
References
- ImageNet. http://www.image-net.org
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
- https://keras.io/api/applications/resnet/#resnet50-function
Resnet101 a convolutional neural network that is 101 layers deep. The default image size is 224x224 pixels but it can be adjusted to any value.
This network in MIB for MATLAB can be initialized using a pretrained version of the network trained on more than a million images from the ImageNet database.
References
- ImageNet. http://www.image-net.org
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
- https://github.com/KaimingHe/deep-residual-networks
XCeption is a convolutional neural network that is 71 layers deep. It is the most computationally intense network available now in DeepMIB for the patch-wise workflow. The default image size is 299x299 pixels but it can be adjusted to any value.
This network in MIB for MATLAB can be initialized using a pretrained version of the network trained on more than a million images from the ImageNet database.
References
- ImageNet. http://www.image-net.org
- Chollet, F., 2017. "Xception: Deep Learning with Depthwise Separable Convolutions." arXiv preprint, pp.1610-02357.
Network filename
The Network filename button allows to choose a file for saving the network or for loading the pretrained network from a disk.- When the Directories and preprocessing or Train tab is selected, press of the this button defines a file for saving the network
- When the Predict tab is selected, a user can choose a file with the pretrained network to be used for prediction
The GPU ▼ dropdown
define execution environment for training and prediction
- Name of a GPU to use, the dropdown menu starts with the list of available GPUs to use; select one that should be used for deep learning application
- Multi-GPU, use multiple GPUs on one machine, using a local parallel pool based on your default cluster profile. If there is no current parallel pool, the software starts a parallel pool with pool size equal to the number of available GPUs. This option is only shown when multiple GPUs are present on the system
- CPU only, do calculation using only a single available CPU
- Parallel (under development), use a local or remote parallel pool based on your default cluster profile. If there is no current parallel pool, the software starts one using the default cluster profile. If the pool has access to GPUs, then only workers with a unique GPU perform training computation. If the pool does not have GPUs, then training takes place on all available CPU workers instead
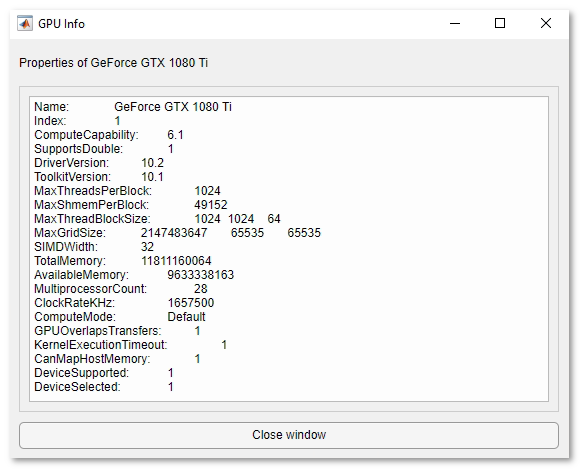
GPU information dialog
The Eye button
Load the network file specified in the Network filename field and perform its check.
This operation differs from pressing the Check network button in the 'Train' panel. When you press this button, the network stored in the file is loaded instead of generating it using the parameters in the 'Train' panel.
Back to Index --> User Guide --> Menu --> Tools Menu --> Deep learning segmentation